

Co je systém? Je to hardware i software, kteří se navzájem koordinují, aby poskytovaly služby, které po nich chceme, jako zobrazení webových stránek, posílání e-mailů nebo provoz oblíbených aplikací, jako OpenVPN nebo GitLab.
Systém má 4 základní prvky:
- CPU (Central Processing Unit)
- Paměť (RAM)
- Jádro (Kernel)
- Network Manager
Jak funguje RAM na Linuxu a jak poznat problém, jsme už psali a teď se zaměříme na CPU.
CPU
Jedná se o centrální procesorovou jednotku, která umí vykonávat strojové instrukce, ze kterých je tvořen např. software a umí obsluhovat jeho vstupy a výstupy. Na serveru CPU čte požadavky uživatele, zpracovává data nebo řeší síťovou komunikaci.

VPS Centrum
Vyzkoušejte zdarma naši aplikaci pro správu serveru a domén. Budete si připadat jako zkušený administrátor.
CPU Load
Matematická definice znamená množství práce, které CPU provádí, jako procento z celkové kapacity. Každý proces, který čeká na CPU zvyšuje zátěž o 1 a proces, který je obsluhován snižuje naopak zátěž o 1.
Load Average (průměr zatížení) je míra, kolik úkolů čeká ve frontě na spuštění jádra po určitou dobu. Nejen čas CPU, ale i aktivita disku po určitou dobu.
První číslo = Průměr za 1 minutu
Druhé číslo = Průměr za 5 minut
Třetí číslo = Průměr za 15 minut
Když zadáte příkaz uptime, tak uvidíte:
#uptime
16:48:24 up 4:11, 1 user, load average: 2.25, 3.40, 3.46
Interpretace:
Freelo - Nástroj na řízení úkolů a projektů
Přidej se, pozvi svůj tým a klienty, rozděl práci a sleduj, jak se úkoly dají do pohybu.
- Když je průměr 0.0, tak to znamená, že je systém v “idle” nebo-li nečinný a nemá, co na práci.
- Když je 1 minutový průměr větší než 5 a 15 minutový, znamená to, že se zátěž zvyšuje
- A naopak. Když je 1 minutový průměr menší než 5 a 15 minutový, tak to znamená, že se zátěž zmenšuje.
- Když jsou čísla větší než počet procesorů, tak to může znamenat výkonnostní problém. Např., když máte pouze 2 procesory, tak v příkladu nahoře vidíte, že zátěž je větší než 2, takže CPU nestíhá a je třeba hledat příčinu.
Tohle je opravdu pouze špička ledovce, ale pro účely našeho článku to bude stačit. Pokud máte spousty času a chuť dozvědět se o tomto tématu více, tak doporučujeme článek v angličtině od Brendana Grega, kde se tématu věnuje opravdu do detailu, a odkazuje se na něj i samotný Red Hat.
CPU Utilization (Využití CPU)
To je doba, kdy je CPU v tzv. nečinném módu (idle). Využívá se jako měřítko toho, jak moc je CPU v dané chvíli vytížené.
CPU steal time
Steal time je procento času, když virtuální procesor čeká na fyzický procesor, zatímco hypervisor obsluhuje jiný virtuální procesor. To se děje ve virtualizovaných prostředích, jako jsou např. AWS, GCP, Azure, vSphere, KVM a Xen.
Chcete-li zobrazit čas krádeže v systému Linux, spusťte příkazový řádek a napište “top” a hledejte zkratku “st”.
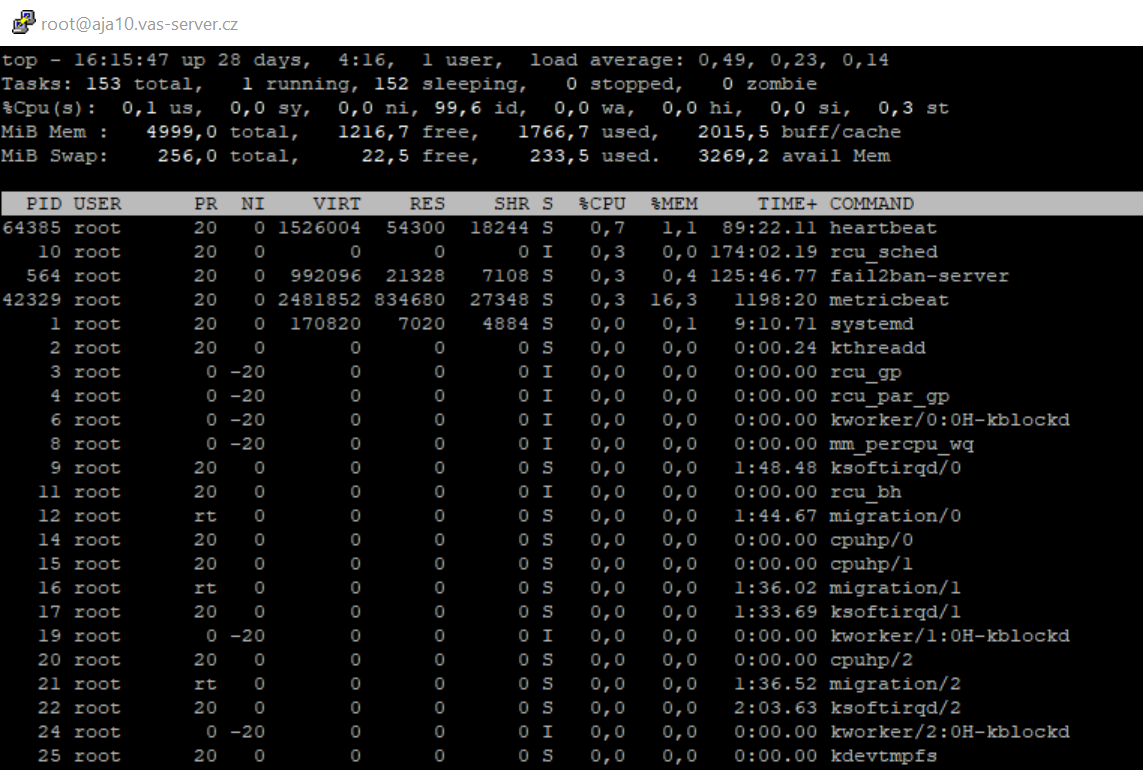
Dopad metriky CPU steal time se vždy projevuje v pomalosti, ale může mít hlubší dopad na infrastrukturu. Zde jsou nějaké příklady:
- Pomalejší načítání stránky
- Pomalé dotazy na databázi
- Pomalejší zpracování e-mailů
- Zvýšená velikost fronty asynchronních úkolů, kvůli nedostatků prostředků
Hlavní příčina problému steal time je, že virtuální server potřebuje více CPU, než dokáže fyzický server momentálně nabídnout nebo vaše aplikace už spotřebuje veškeré zakoupené prostředky a je nutné navýšení.
Tento problém byste měli začít řešit pokud hodnota %st je větší než 10% po dobu 20 minut a více.
Co jsou CPU vlákna (threads)?
Všechny centrální procesorové jednotky mají vlákna, ale co to přesně znamená? Vlákna umožňují vašemu CPU provádět více věcí najednou. Pokud tedy chcete spustit více procesů, které jsou velmi intenzivní, budete potřebovat procesor se spoustou vláken, kterému se říká multi-threads.
Co jsou CPU jádra (core´s)?
Jádro CPU je součástí něčeho zásadního pro jeho existenci nebo charakteru. V počítačovém systému se i samotnému CPU říká jádro.
V zásadě existují dva typy jádrového procesoru:
- Jednojádrový procesor
- Vícejádrový procesor
U jednojádrového procesoru existují dva problémy:
- Chcete-li úkoly provádět rychleji, musíte zvýšit čas pro vykonání daného procesu
- Prodloužení času ale zvyšuje spotřebu energie a odvod tepla na extrémně vysokou úroveň, což činí procesor neefektivní.
Řešení poskytované více-jádrovým procesorem:
- Vytvořením dvou nebo více jader na stejné matrici zvýšíte výpočetní výkon, zatímco se udržuje rychlost a teplota na efektivní úrovni.
- Procesor se dvěma jádry dokáže zpracovat instrukce s podobnou rychlostí jako jednojádrový procesor, ale více-jádrový proces spotřebovává méně energie.
Zde jsou některé výhody více-jádrového procesoru:
- Více tranzistorů na výběr
- Kratší spojení
- Nižší kapacita
- Malý okruh může pracovat vysokou rychlostí
Rozdíl mezi jádrem a vláknem
|
Parametr |
Jádro |
Vlákno |
|
Definice |
Jádra CPU znamenají skutečnou hardwarovou komponentu |
Vlákna odkazují na virtuální komponentu, které spravují úkoly |
|
Proces |
CPU je “krmen” úkoly z vlákna. Proto k druhému vláknu přistupuje, pouze když informace odeslané prvním vláknem nejsou spolehlivé |
Existuje mnoho různých variant, jak může CPU interagovat s více vlákny |
|
Implementace |
Dosaženo pomocí prokládání provozu |
Provádí se pomocí více CPU |
|
Výhoda |
Zvýší množství zpracovaných procesů najednou |
Lepší propustnost a zrychlený výpočet |
|
Možnosti |
Jádro využívá přepínání obsahu nebo-li content switching |
Využívá více procesorů pro provoz většího počtu procesů |
|
Vyžadovány jednotky zpracování |
Vyžaduje pouze procesní signál jednotky |
Vyžaduje více zpracovatelských jednotek |
|
Příklad |
Spuštění více aplikací najednou |
Spuštěný webový prohledávač v clusteru |
I/O wait – Co to znamená?
I / O wait je procento času, po který byly CPU nečinné, během kterých měl systém nevyřízené I / O požadavky na disk.
Když používáte Linux, tak si všimnete, že CPU a jeho jádra fungují v následujících stavech:
- us = user/uživatel
- sy = systém
- id = idle/nečinný
- ni = nice (prioritizace procesů)
- si = software interrupts/softwarová přerušení
- hi = hardware interrupts/hardwarová přerušení
- st = CPU steal time
- wa = wait/čekání
Pozor na „idle“ a „wait“ nejsou stejné! „Idle“ v CPU znamená, že není k dispozici žádná pracovní zátěž, zatímco „wait“ (I/O wait) označuje, kdy CPU čeká v nečinném stavu na nevyřízené požadavky z disku.
Pokud je CPU nečinný, jádro zjistí, zda existují nějaké nevyřízené I/O požadavky (tj. SSD nebo NFS) pocházející z CPU. Pokud existují, tak se zvýší počítadlo „wait“. Pokud nic, tak místo toho se zvýší počítadlo „idle“.
Nejčastěji problém bývá v dotazech do databáze, protože ty často zapisují a čtou data na disku. Na konci článku najdete, jak i samotný PhpMyadmin dokáže poradit s optimalizací databáze. Můžete mrknout i na náš článek jak zrychlit, web, server a databáze.
Scénář č. 1 – Vysoký CPU Load a nízké využití CPU
To může nastat, když máte proces, který zůstává blokován v I/O kvůli zaneprázdnění disku. Například jednoduché volání mkdir může vést k vysokému zatížení procesoru, pokud je blokováno v I/O.
Scénář č. 2 – Vysoké využití CPU, ale nízký CPU load
To může nastat, když máte jedno vlákno / proces, který spotřebovává celé jádro, a nemáte příliš mnoho procesů spuštěných nebo čekajících na CPU.
Nástroje pro troubleshooting CPU
Teď se podíváme na nástroje, které nám pomohou odhalit problémy s CPU a najít i konkrétní viníky ve formě procesů.
- uptime
- htop / top
- prioritizace procesů pomocí příkazu “nice”
- iotop / iostat
- monitoring procesů ve VPS Centru
- poradce v PhpMyAdmin
Příkaz – Uptime
Uptime poskytuje informace:
- jak dlouho je systém spuštěný
- o počtu aktivních uživatelů
- průměrech zatížení v rozpětí 1 minuta, 5 minut a 15 minut.
Poslední tři čísla vám pomohou pochopit, zda je špička využití dlouhodobá nebo krátkodobá. Desetinné číslo představuje počet aktivních úkolů požadujících, aby prostředky CPU provedly akci.
Pokud je poslední číslo příliš vysoké je to problém, který se musí vyřešit. Pokud máte pouze 1 jádro s hodnotou např. 1,5, tak rozdíl 0,5 představuje procento počtu procesů, které čekají na provedení. Bezproblémová hodnota s 1 jádrem je tedy pod hodnotou 1.0, pokud máte jádra 2, tak zase bezproblémová hodnota je pod 2.0 atd..
Jak jste na tom s počtem jader zjistíte pomocí příkazu:
cat /proc/cpuinfo | grep processor

Tady zjistím, že mám 3 jádra, takže v příkazu uptime vše pod hodnotou 3.0 bude v pořádku.

Tady je vše v pořádku a s klidem můžu SSH vypnout. Pokud by hodnoty byly více, jak 3,5 tak bych měl hledat důvod tohoto přetížení.
Tohle je takový první příkaz, který vám rychle ukáže, jestli je třeba podstupovat další kroky.
Příkaz – top / htop
Příkaz top / htop poskytuje real-time informace o procesech. Udává průměry zatížení podobné výstupu uptime a zahrnuje také metriky na CPU, když po spuštění příkazu top zmáčknete „1“. Tak se veškeré procesy, které nejvíce vytěžují CPU seřadí od těch nejvytěžovanějších.
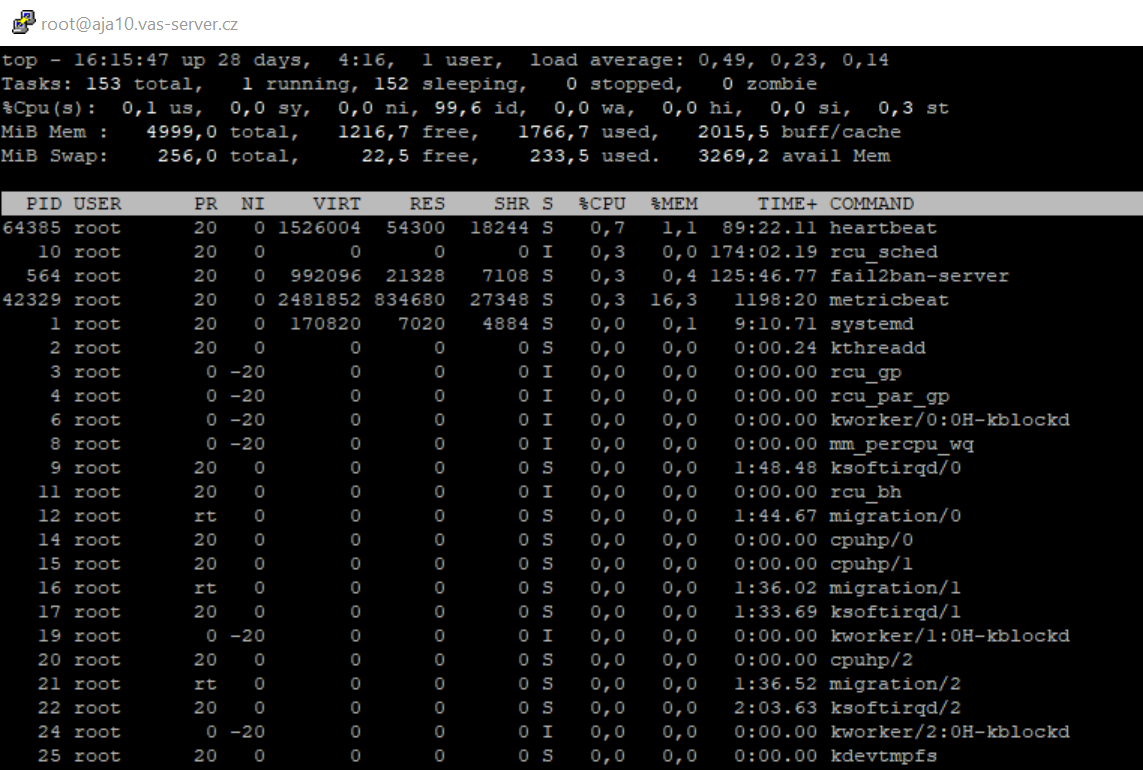
Když používáte Linux, tak si všimnete, že CPU a jeho jádra fungují v následujících stavech:
- us = user/uživatel
- sy = systém
- id = idle/nečinný
- ni = nice (prioritizace procesů)
- si = software interrupts/softwarová přerušení
- hi = hardware interrupts/hardwarová přerušení
- st = CPU steal time
- wa = wait/čekání
Příkaz htop je velice podobný, jen mu chybí stavy z horního sloupce příkazu top. Naopak je barevnější a uživatelsky přívětivější. Pokud jej na systému nemáte nainstalovaný, stačí zadat příkaz:
apt-get install htop
htop
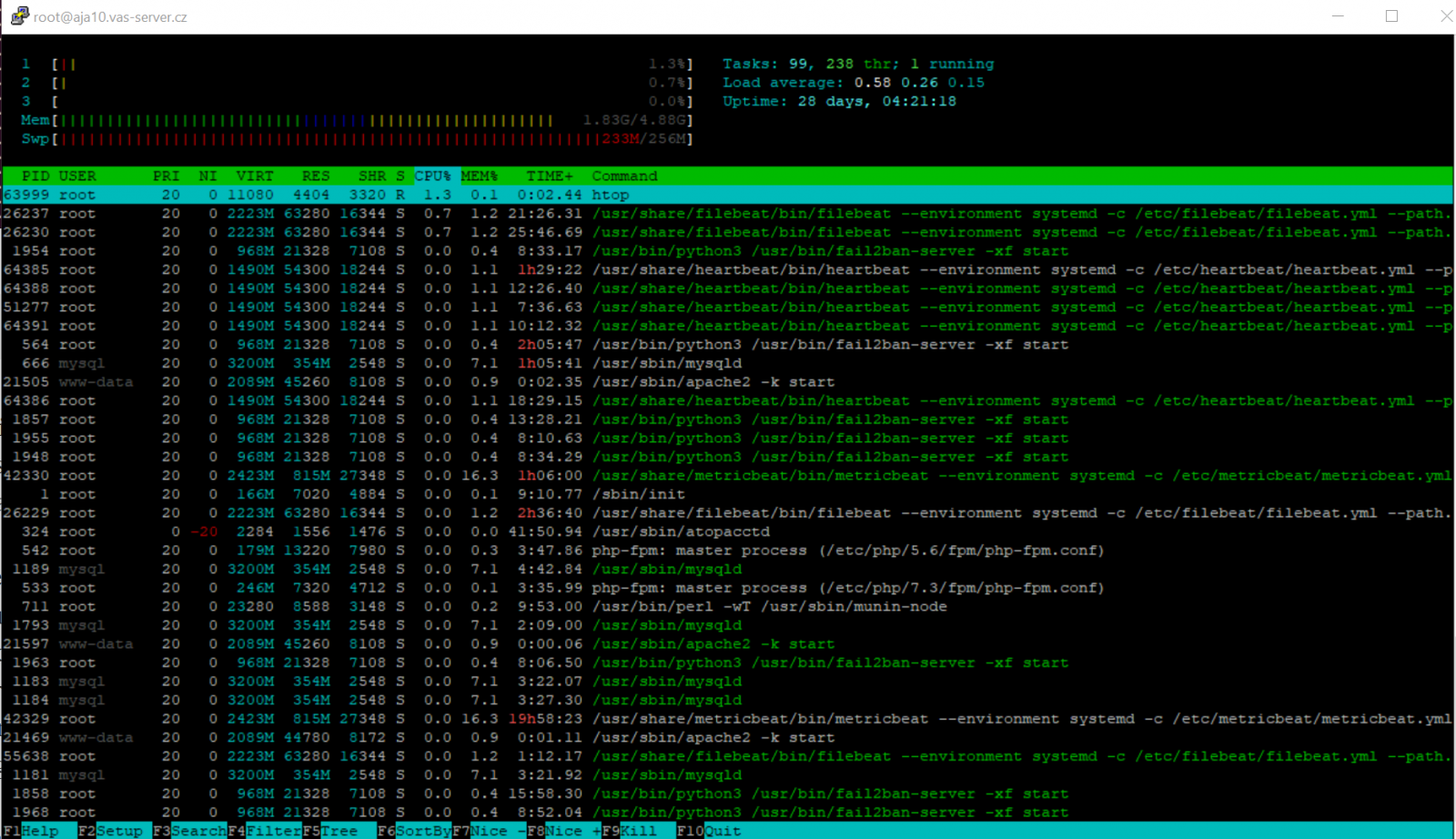
Na htopu je super, že v reálném čase vidíte i graficky, jak moc jsou všechna jádra nebo RAM vytížená. Jak moc si sahá do swapu a jen ty nejdůležitější čísla, takže to je přehledné.
Dole máte možnosti, třeba pomocí (F5) poskládat procesy do stromové struktury, (F9) zabít konkrétní procesy nebo (F7) přiřazovat jednotlivým procesům prioritu.
Bohužel zabíjením procesů výkonost systému nijak neoptimalizujeme. Jen problém budeme neustále oddalovat, ALE můžeme limitovat prostředky CPU, které daný proces dostane.
Prioritizace procesů pomocí příkazu “nice”
nice je příkaz, který má schopnost určovat priority jednotlivých procesů. Ve výchozím nastavení začíná nový proces s “nice” hodnotou 0. Hodnoty “nice” by měly ležet mezi -20 a 19. Čím vyšší je hodnota, tím je proces, důležitější a bude mít přednost před těmi procesy, které takovou prioritu nemají.
Řekněme, že máte skript testuju.sh, který není nijak kritický pro běh systému a tím pádem nemusí mít přednost. Můžeme mu dát tedy zápornou hodnotu pomocí příkazu:
nice -10 /root/bin/testuju.sh
Tím pádem všechny procesy, které mají hodnotu -9 a méně budou mít před tímto procesem přednost a prostředky CPU je bude obsluhovat rychleji.
Řekněme, ale že tento skript je naopak pro běh systému kritický a potřebujeme, aby měl mnohem větší prioritu než většina procesů, které na systému běží. Tak zadáme:
nice –17 /root/bin/testuju.sh
Takhle bude mít přednost před většinou procesů, a bude vybaven přednostně. To už by se ve stejné době museli potkat veškeré procesy, které budou mít hodnotu nice +18, +19 nebo +20.
Díky tomuto příkazu dokážete optimalizovat procesy na systému a říkat CPU, které procesy jsou pro běh systému důležitější a mají mít přednost.
Příkaz – iotop / iostat
Iotop zobrazí aktivity disku v reálném čase. Iotop sleduje informace o využití I/O z jádra Linuxu a zobrazuje tabulku aktuálního využití I/O prostřednictvím procesů nebo vláken v systému.
Zobrazuje read/write z každého procesu/vlákna. Také zobrazuje procento času, které vlákno/proces strávil výměnou nebo čekáním na I/O.
Hodnoty Total DISK READ a Total DISK WRITE představují celkový bandwidth pro čtení a zápis mezi procesy a vlákny jádra na jedné straně a subsystémem jádra na straně druhé.
Hodnoty Current DISK READ / DISK WRITE představují odpovídající bandwidth pro skutečný proud I / O mezi subsystémem jádra a základním hardwarem (HDD, SSD atd.).
Pokud iotop nemáte nainstalovaný, můžete tak provést příkazem na Debian / Ubuntu
apt-install iotop
iotop
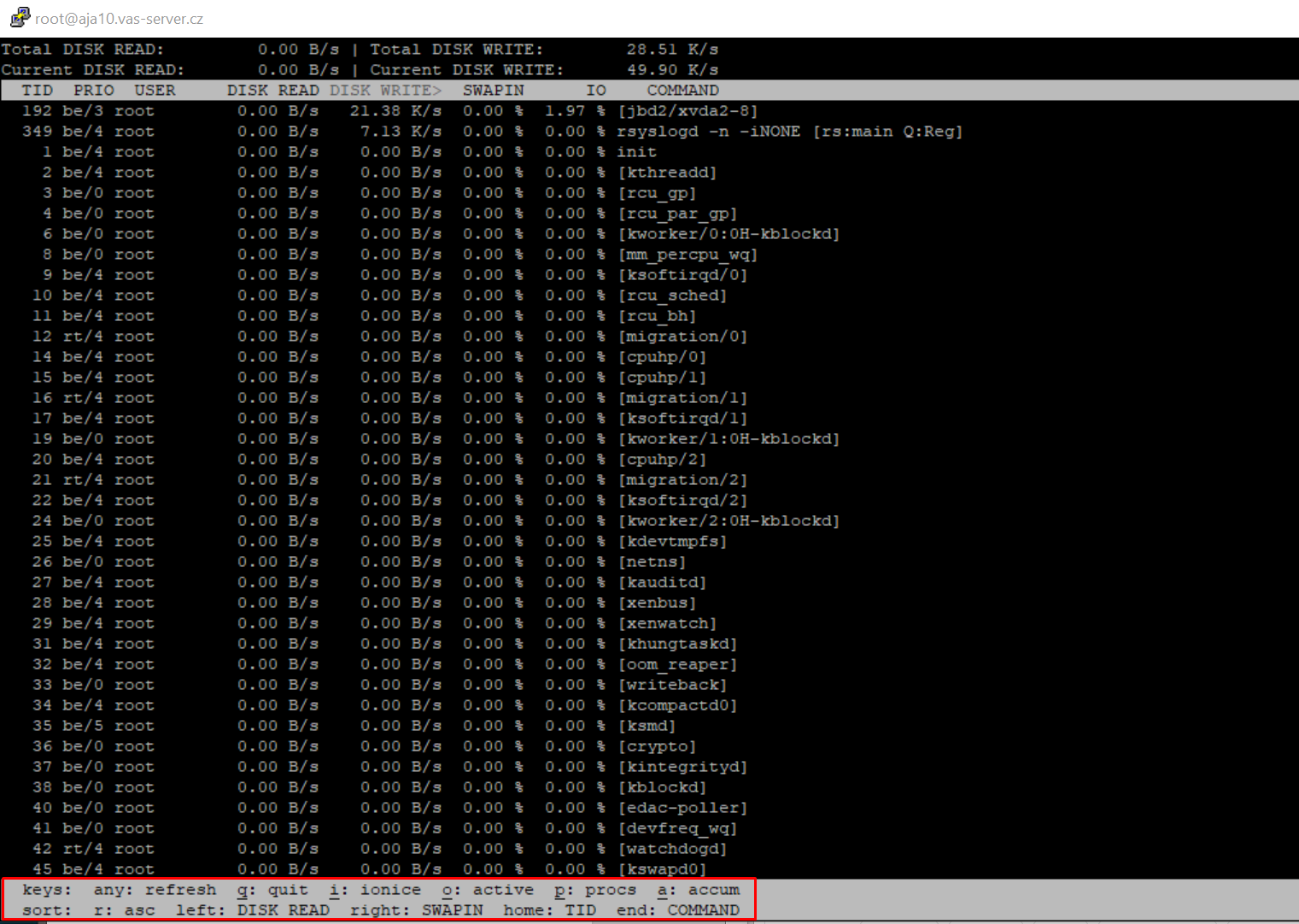
Můžete šipkami upravovat, jestli mají být nahoře procesy např. s největším disk read/write
Pomocí atributu -o nebo –only se vypíše tabulka pouze s procesy, které momentálně využívají disk.
iotop -o
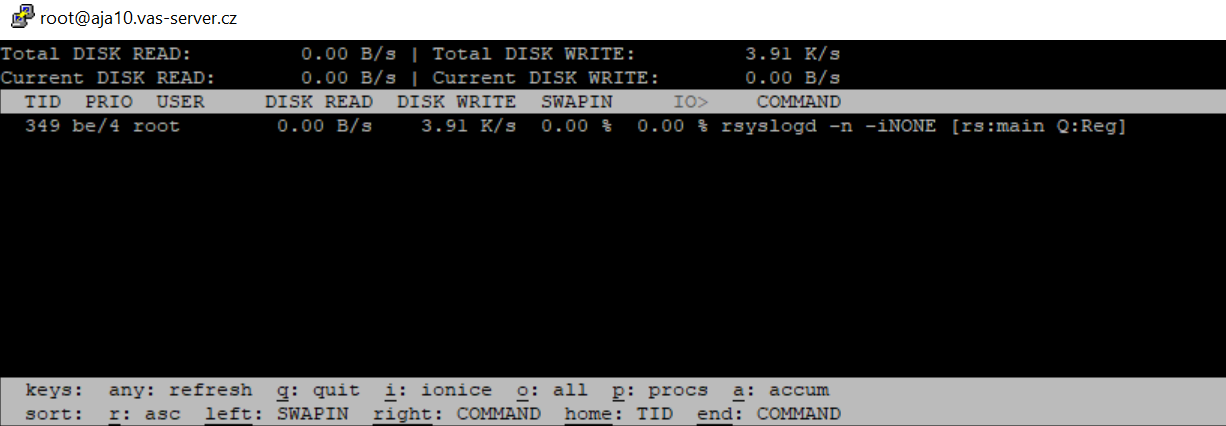
Sloupec I/O ukazuje využití vstupu / výstupu každého procesu, který zahrnuje disk a swap.
Sloupec swapin zobrazuje pouze využití swapu každého procesu. Více o swap in/out v našem článku RAM na Linuxu.
Příkaz – iostat
Iostat se používá k hlášení statistik centrální procesorové jednotky (CPU) a statistik vstupů a výstupů pro zařízení a diskové oddíly (partitions).
Příkaz iostat se používá k monitorování načítání vstupních/výstupních zařízení systému sledováním času, kdy jsou zařízení aktivní ve vztahu k jejich průměrným rychlostem přenosu.
Příkaz iostat generuje reporty, které lze použít ke změně konfigurace systému pro lepší vyvážení vstupního/výstupního zatížení mezi fyzickými disky.
Všechny statistiky se vykazují při každém spuštění příkazu iostat. Na víceprocesorových systémech se statistiky CPU počítají v systému jako průměr mezi všemi procesory.
Příkaz iostat generuje dva typy reportů:
- o využití CPU
- o využití zařízení.
Na Debian/Ubuntu jej nainstalujete pomocí příkazu:
apt install sysstat
iostat
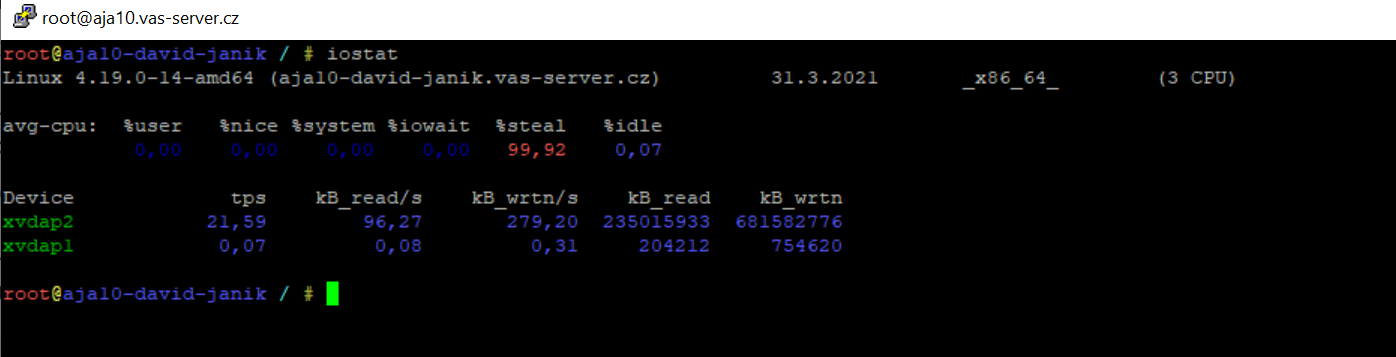
Zde krásně uvidíte, co vytěžuje CPU, jestli to jsou procesy uživatele, systému nebo I/O.
Pro podrobnější výpis použijte ještě atribut -x
iostat -x

Tady uvidíte podrobnější statistiky pro každý diskový oddíl, který se v systému nachází.
Můžete použít ještě atribut -m, aby se hodnoty zobrazovaly v MB místo kB.
Bohužel iostat není “real-time” vyhodnocovač. Pro aktualizované reporty např. 5 reportů s aktualizací každých 10 vteřin, zadáte příkaz.
iostat -x 10 5
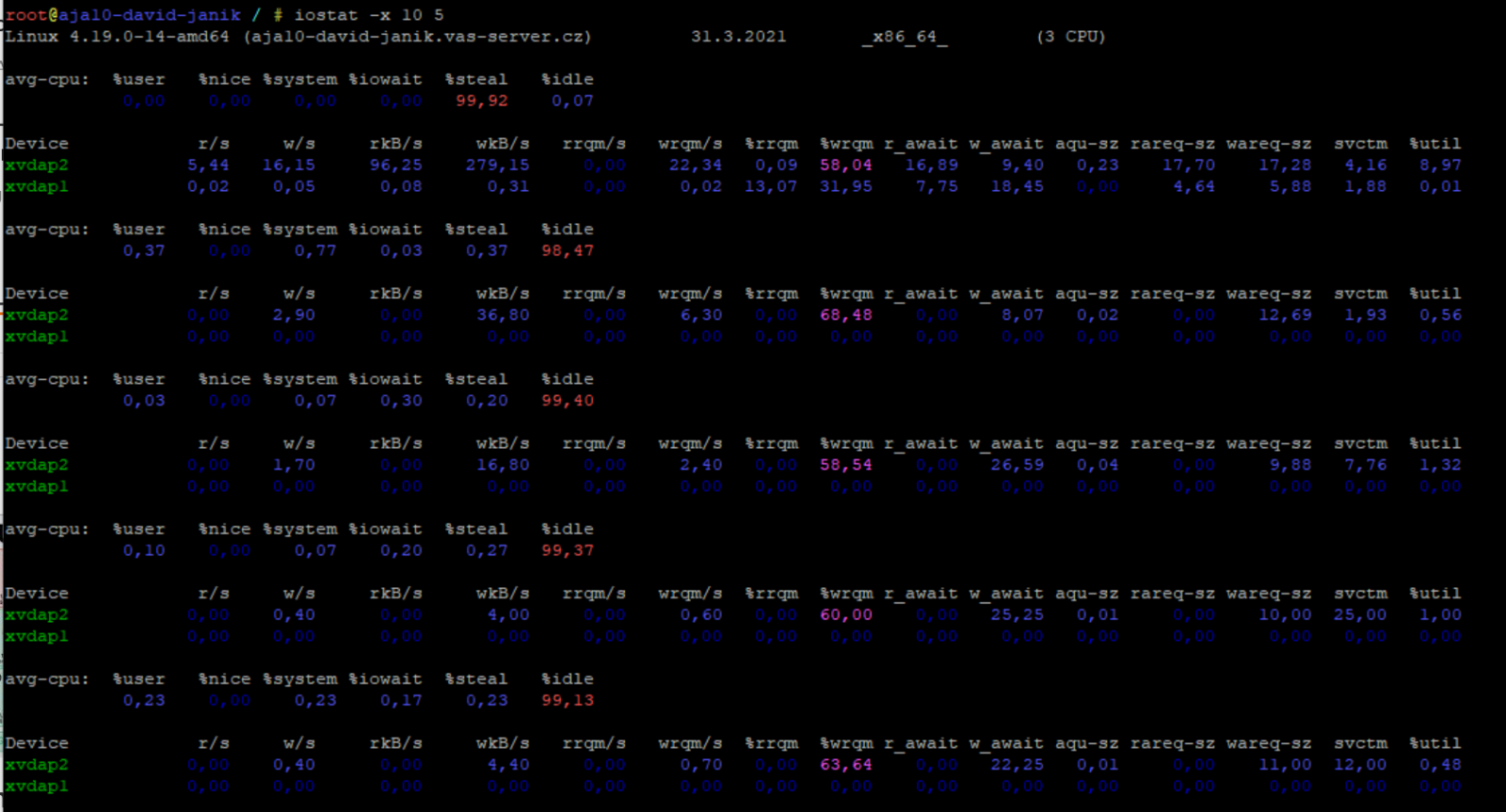
Je to takový podrobnější rozpis I/O než pouze sloupec “wait” v příkazu top. Iostat začnete používat, jakmile víte, že je problém v I/O a pomůže vám identifikovat problém.
Přehled v našem VPS Centru
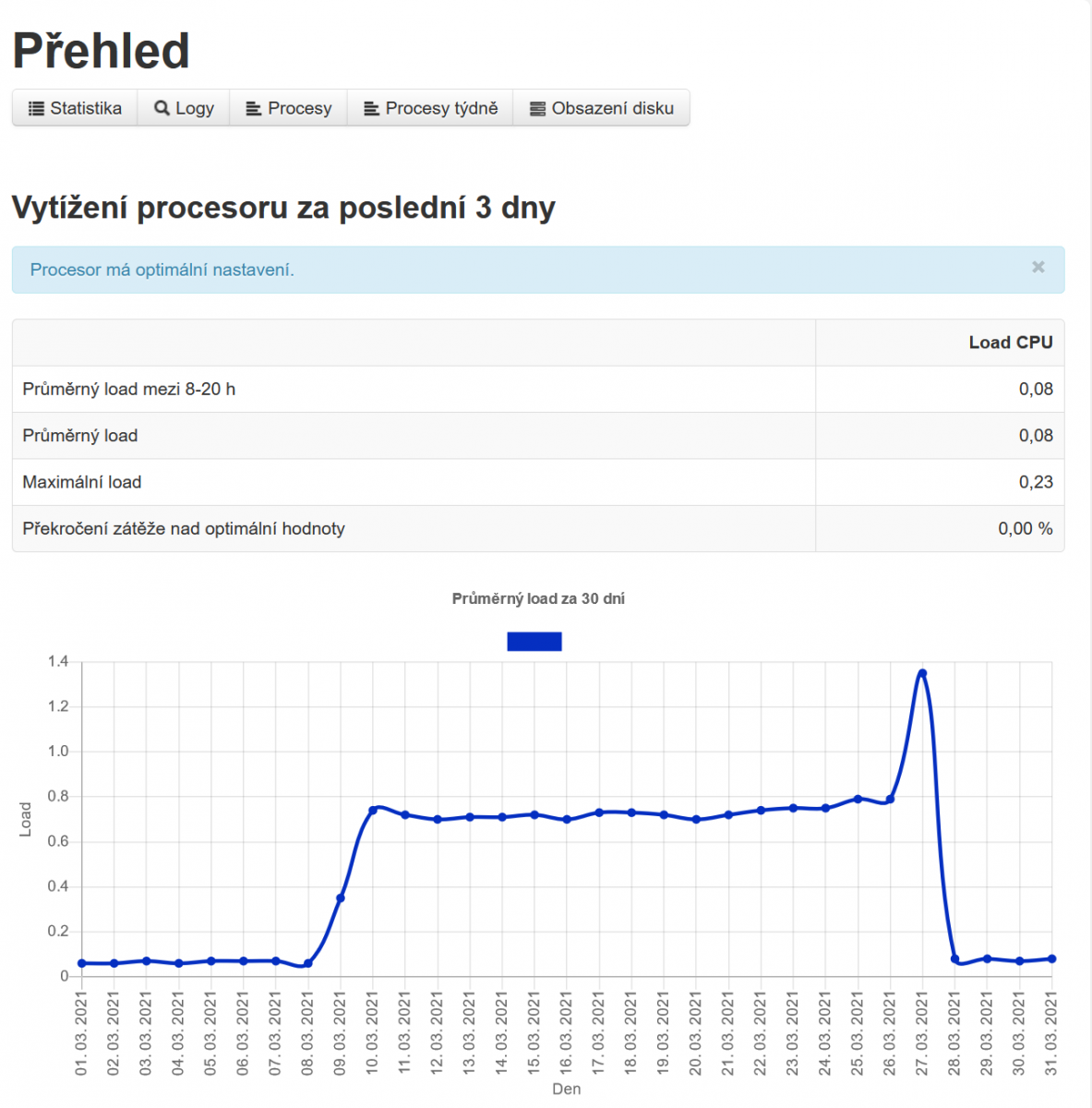
Pro zjištění problému si vystačíte i s našim VPS Centrem v sekci Přehledy, uvidíte průměrné vytížení procesoru za poslední 3 dny:
- avg. load mezi 8-20h
- avg. load
- max. load
- překročení zátěže nad optimální hodnoty (tedy, když máte 1 jádro a avg. load je 1,5, tak překračuje optimální hodnoty o 50%)
A pak samozřejmě, jak jde průměrný load za posledních 30 dní v grafu.
Monitoring procesů ve VPS Centru
Naše VPS Centrum umí pro PHP, MySQL a jednotlivé domény hlídat tyto hodnoty:
- průměrnou spotřebu času CPU (v sekundách)
- počet různých aktivních procesů,
- celkový počet zaznamenaných procesů
- průměrná spotřeba RAM ( v GB)
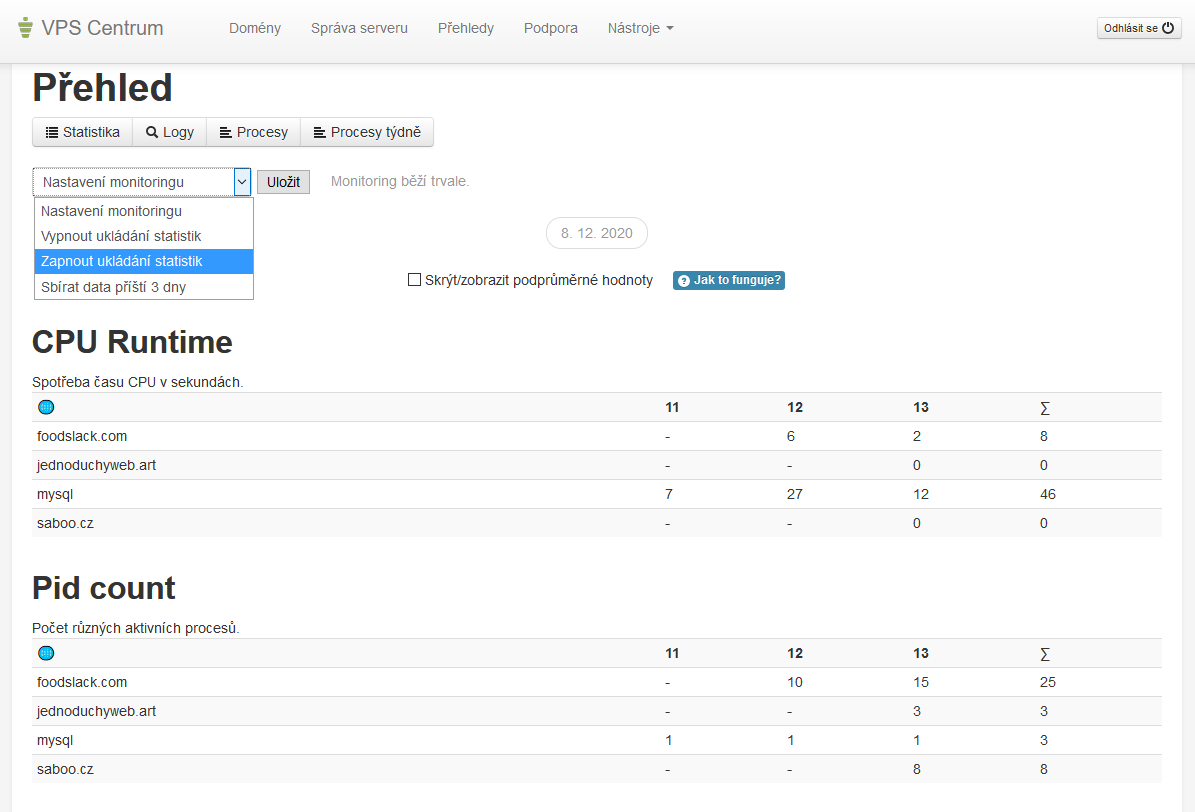
Defaultně jsou statistiky vypnuté a v sekci Přehledy > Procesy vyberte možnost ukládat statistiky. Můžete data sbírat i jenom pro následující 3 dny, pak se monitoring automaticky vypne, aby zbytečně nezatěžoval server.
Doporučujeme monitoring zapínat pouze v případě, když řešíte otázku: „Co vytěžuje můj server?”
Monitoring jasně napoví, jestli je největší zátěž na straně MySQL nebo v rámci zpracování PHP nějaké konkrétní domény.
Na serveru ještě máte užitečný skript ve složce /root/bin/webserver_ip_count.sh, ten ukáže, jaká IP adresa má největší provoz na základě analýzy access logu z webserveru.
To se může hodit, když třeba analyzujete nějaký útok, nebo nějaký web crawler přetěžuje váš server.
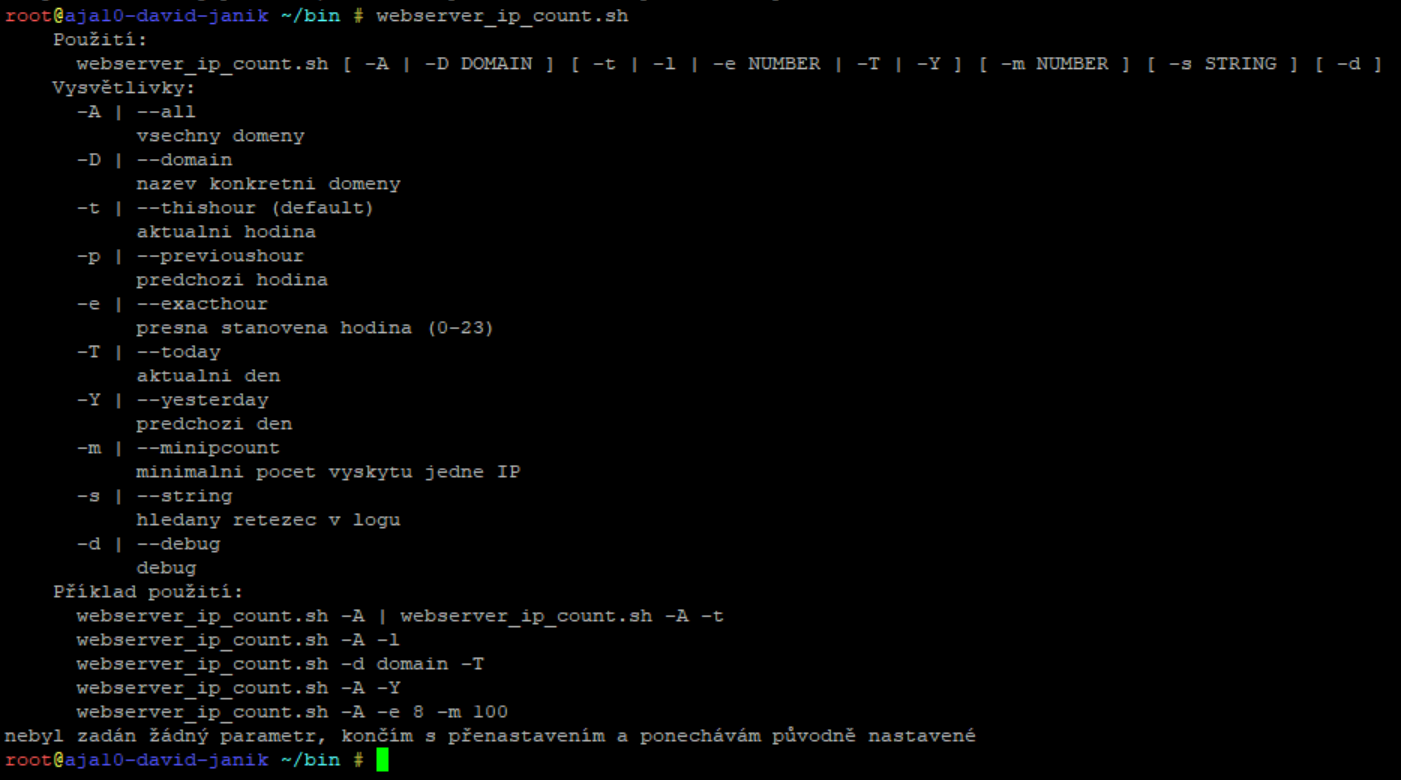
Když chceme skript spustit a analyzovat veškeré domény, tak půjdeme do složky:
cd /root/bin/
a příkaz spustíme:
./webserver_ip_count.sh -A
A dostaneme výstup…
1 40.77.167.94
2 104.131.46.224
2 104.236.55.194
2 123.57.176.147
2 207.46.13.61
11 18.194.196.202
24 91.187.73.114
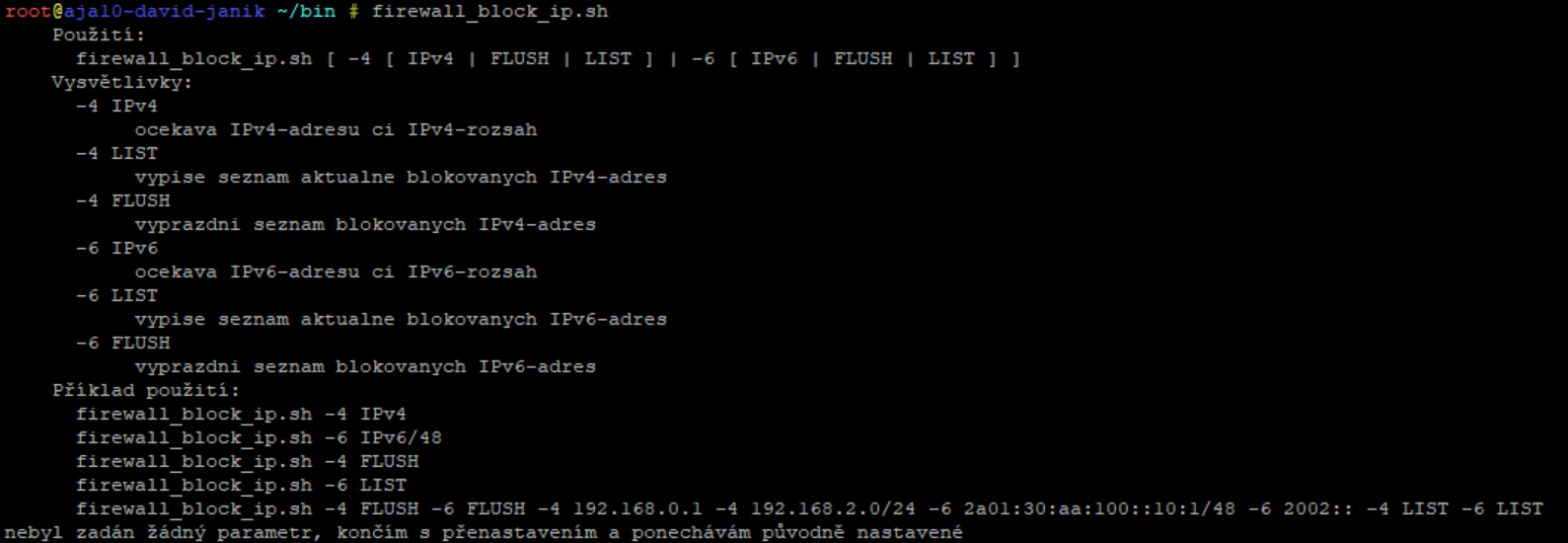
Uvídíme, že poslední IP adresa 91.187.73.114 nám server vytěžuje nejvíc 24 přístupy na web, a můžete použít další skript firewall_block_ip.sh , který tuto IP adresu zabanuje pomocí příkazu ve složce /root/bin/
./firewall_block_ip.sh -4 91.187.73.114
A tato IP adresa bude zablokovaná do rebootu serveru. Můžete blokovat i celé rozsahy, IPv6 adresy nebo si vypsat seznam aktuálně blokovaných adres.
Poradce v PhpMyAdmin
Poslední věc, kterou si dneska ukážeme je poradce v PhpMyAdmin. MySQL běží na serveru neustále a velká část procesů, který si berou prostředky CPU pochází právě odtud. Tak se hodí vědět, všechny možné vychytávky, jak můžete své databáze optimalizovat.
O tomto rádci moc lidí neví, tak jej rádi připomeneme. Stačí se přihlásit do aplikace a jít do sekce Stav > Poradce viz.
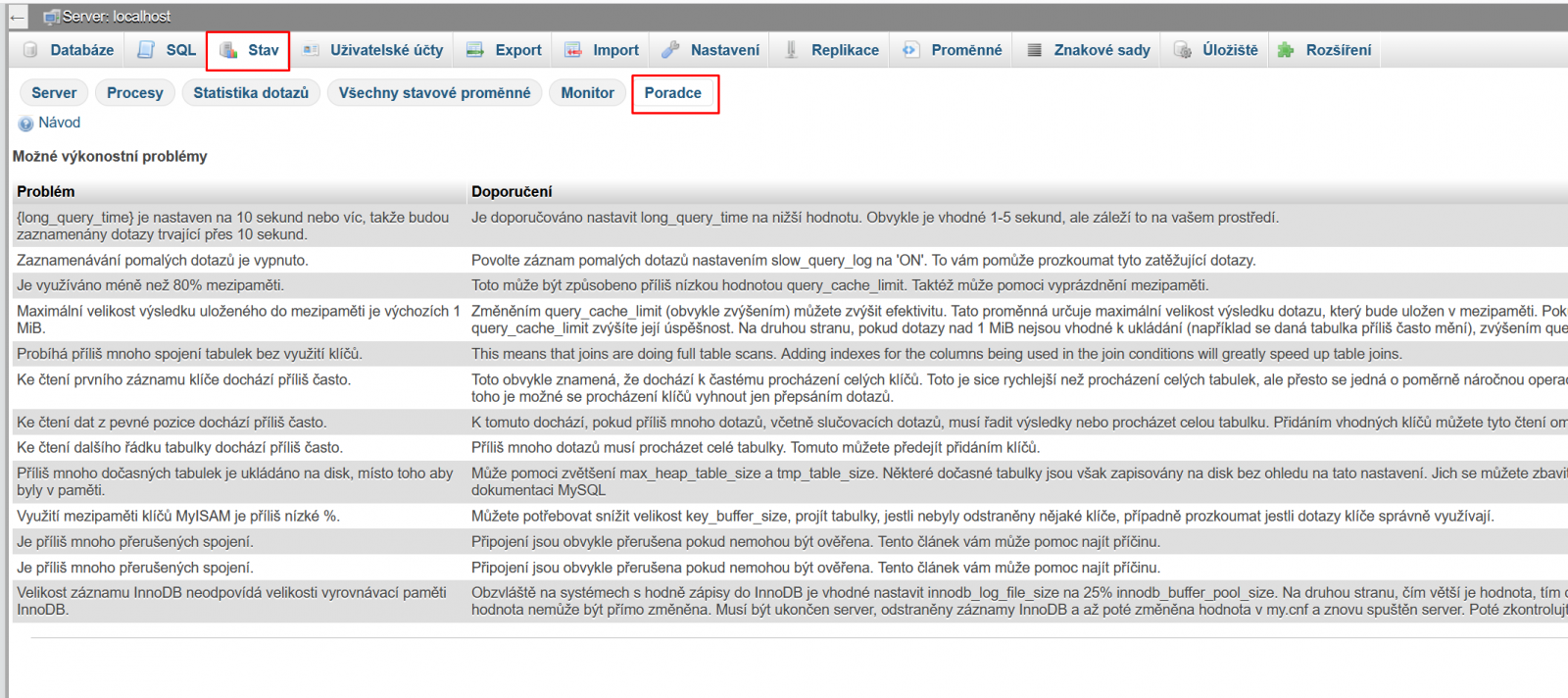
Kde máte 2 sloupce problém a doporučení. Po kliknutí na problém se otevře pop up s podrobnějším popisem.
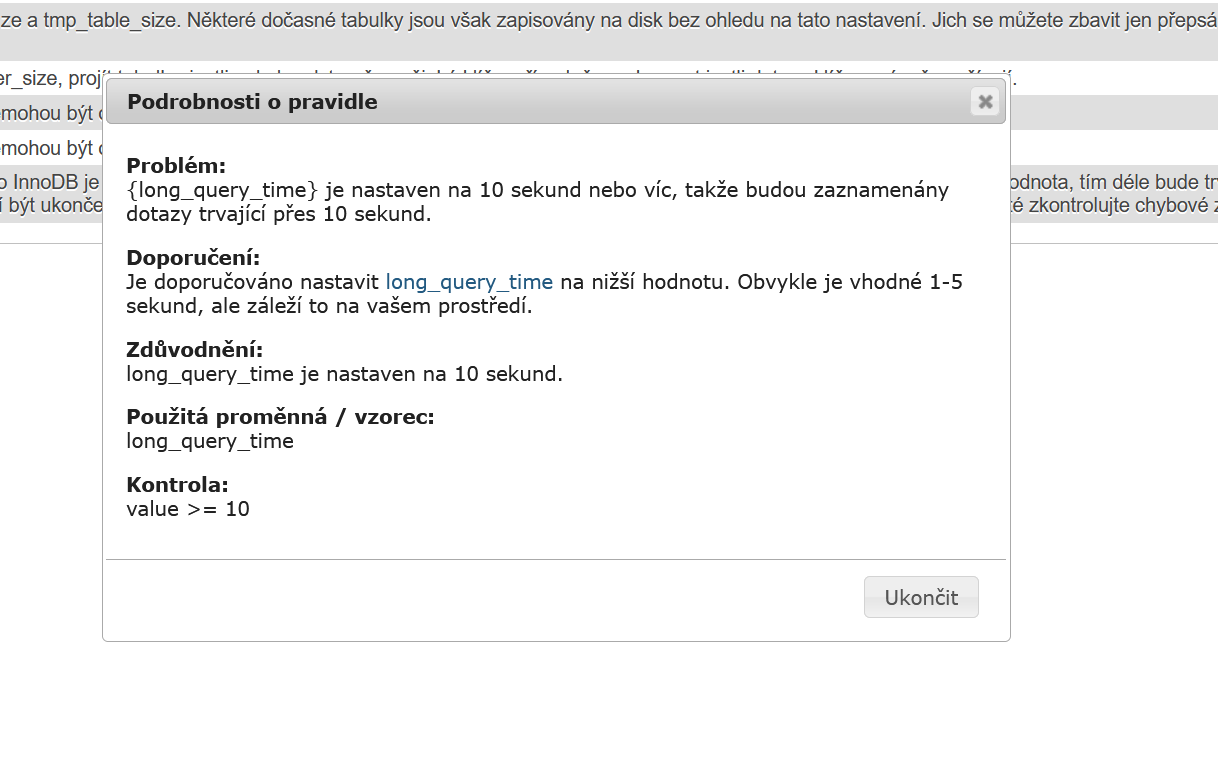
Tak to by pro dnešní článek bylo vše. Přejeme, co nejmenší load!
Můžete si ještě zopakovat článek, jak zrychlit web, server a databáze.

